Flyweight (享元) 模式
享元模式,作用于会产生大量对象的场景,其实现原理是使用缓存,避免创建过多的、重复的对象并提升程序性能。
简单来说,当我们需要一个对象时,一般都是使用 new 来创建一个对象。但是实际情况却是,如果在一段时间内有大量的请求的话,就会产生大量的对象,可是这些对象的内容都大同小异,如果反复的创建、销毁对象,必将影响程序的性能。而享元模式的作用就是用来解决这个问题的。
其实在这里关于缓存的实现可以理解为对“池”的实现,我们都知道,在 String 类中有常量池,在线程中有线程池,它们的作用都是避免创建过多的对象以达到提升性能的目的。所以,在享元模式中,我们将实现一个对象池。一个经典的实现就是使用键值对( Map )。我们以对象之间相同的部分(内在状态)作为键,以不同的部分(外在状态)作为值,当我们从持有缓存的享元工厂中获取享元对象的时候,先判断时候存在我们需要的键,若没有则创建一个新的对象放入缓存中,若存在则使用缓存的对象,以此来达到避免创建过多对象的目的。
Flyweight (享元) 模式的 UML 类图
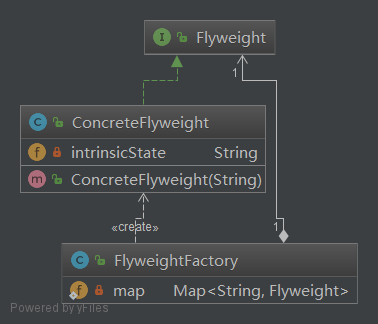
- Flyweight: 享元对象接口或抽象类
- ConcreteFlyweight: 具体的享元对象
- FlyweightFactory: 享元工厂,负责管理享元对象池和创建享元对象
简单的看一下实现:
首先是定义一个享元对象接口:Flyweight
1
2
3
4
5
| public interface Flyweight {
public void operation(String extrinsicState);
}
|
这里要传入的参数就是该享元对象的外部状态 (Extrinsic State),即享元对象间根据情况的不同而会变化的部分
接着是实现了接口的具体的享元对象:ConcreteFlyweight
1
2
3
4
5
6
7
8
9
10
11
12
13
| public class ConcreteFlyweight implements Flyweight{
private String intrinsicState;
public ConcreteFlyweight(String intrinsicState) {
this.intrinsicState = intrinsicState;
}
@Override
public void operation(String extrinsicState) {
System.out.println(intrinsicState + " : " + extrinsicState);
}
}
|
这里的全局变量就是该享元对象的内部状态 (Intrinsic State),即享元对象间不会随着使用情况的不同而变化的部分
最后就是实现享元工厂:FlyweightFactory
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public class FlyweightFactory {
private static Map<String, Flyweight> map = new ConcurrentHashMap<>();
public static Flyweight getFlyweight(String key) {
if (map.containsKey(key)) {
System.out.println("use cache:");
return map.get(key);
} else {
System.out.println("create new:");
Flyweight flyweight = new ConcreteFlyweight(key);
map.put(key, flyweight);
return flyweight;
}
}
}
|
在这一块使用 Map 集合来缓存对象,在获取享元对象的时候会判断是否存在该对象的缓存,若存在则直接获取,否则就创建一个新的对象。这里为了显示这两部分的效果,输出了中间结果
那么接下来就是测试一下
1
2
3
4
5
6
| Flyweight flyweight1 = FlyweightFactory.getFlyweight("key1");
flyweight1.operation("value1");
Flyweight flyweight2 = FlyweightFactory.getFlyweight("key1");
flyweight2.operation("value2");
Flyweight flyweight3 = FlyweightFactory.getFlyweight("key1");
flyweight3.operation("value3");
|
测试结果如下
1
2
3
4
5
6
| create new:
key1 : value1
use cache:
key1 : value2
use cache:
key1 : value3
|
可见,在使用除了第一次使用需要创建对象之外,接下来获取该 key 的对象的时候都不需要创建对象
享元模式的简单实现下
正如上面所说,享元模式适用于可能存在大量重复对象的场景,所以,诸如订票系统这类例子。因为同一类型的票会产生很多份,那么对应的重复对象的创建和销毁就会产生,这将导致程序性能下降和内存占用率的上升
接下来就以订购电影票为例子。简单的分析一下,一张电影票大概含有一下几个元素:电影名,时间,座位和价格,这其中电影名是重复的,座位和时间根据情况的不同是不一样的。
首先就是关于票的接口:Ticket
1
2
3
4
5
| public interface Ticket {
public void printTicket(String time, String seat);
}
|
printTicket() 方法是根据时间和作为打印出相应的电影票
然后就是具体的电影票:MovieTicket
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public class MovieTicket implements Ticket {
private String movieName;
private String price;
public MovieTicket(String movieName) {
this.movieName = movieName;
price = "Price " + new Random().nextInt(100);
}
@Override
public void printTicket(String time, String seat) {
System.out.println("+-------------------+");
System.out.printf("| %-12s |\n", movieName);
System.out.println("| |");
System.out.printf("| %-12s|\n", time);
System.out.printf("| %-12s|\n", seat);
System.out.printf("| %-12s|\n", price);
System.out.println("| |");
System.out.println("+-------------------+");
}
}
|
在创建这电影票的对象时,需要根据电影名来创建,也就是说电影名是作为享元对象的键。这里为了效果,在 printTicket() 方法中,格式化打印输出了一张电影票大概的样子。
那么享元工厂跟之前写的差不了多少:TicketFactory
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public class TicketFactory {
private static Map<String, Ticket> map = new ConcurrentHashMap<>();
public static Ticket getTicket(String movieName) {
if (map.containsKey(movieName)) {
return map.get(movieName);
} else {
Ticket ticket = new MovieTicket(movieName);
map.put(movieName, ticket);
return ticket;
}
}
}
|
接下来就可以测试一下了
1
2
3
4
5
6
| MovieTicket movieTicket1 = (MovieTicket) TicketFactory.getTicket("Transformers 5");
movieTicket1.printTicket("14:00-16:30", "Seat D-5");
MovieTicket movieTicket2 = (MovieTicket) TicketFactory.getTicket("Transformers 5");
movieTicket2.printTicket("14:00-16:30", "Seat F-6");
MovieTicket movieTicket3 = (MovieTicket) TicketFactory.getTicket("Transformers 5");
movieTicket3.printTicket("18:00-22:30", "Seat A-2");
|
相同的电影名,但是根据不同的时间和座位号打印出不同的票
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| +-------------------+
| Transformers 5 |
| |
| 14:00-16:30 |
| Seat D-5 |
| Price 4 |
| |
+-------------------+
+-------------------+
| Transformers 5 |
| |
| 14:00-16:30 |
| Seat F-6 |
| Price 30 |
| |
+-------------------+
+-------------------+
| Transformers 5 |
| |
| 18:00-22:30 |
| Seat A-2 |
| Price 29 |
| |
+-------------------+
|
总结
虽然享元模式的实现非常简单,但是它的应用场景十分重要。
- 优点:使用享元模式可以减少应用程序创建的对象,降低程序内存的占用,增强程序的性能
- 缺点:因为需要将一个对象的外部状态和内部状态分离,所以系统的复杂性也提高了
END.
源码地址
