
前言
本次Hadoop分布式环境搭建,最终目标是使用三个虚拟机来形成一个小的分布式集群,并可以在本机中通过主机名加端口的方式访问到虚拟机中的 HDFS 和 YARN,也就是说:可以在本机(Windows/Mac OS/Linux)中开发,再通过远程连接虚拟机来运行 MapReduce 程序。
本次搭建过程中,所用资源及其版本如下如下:
- 虚拟机: VMware Workstation 15.5 pro
- CentOS: CentOS-7-x86_64-DVD-2003
- JDK: jdk-8u251-linux-x64
- Hadoop: hadoop-2.6.0-cdh5.15.0
- 远程连接工具: Xshell 和 Xftp (个人可以通过邮件获取免费正版)
注意 本文不涉及软件破解过程,如果介意该过程可以使用 VirtualBox 作为替代,虽然在使用流程上会与 VMware 稍有不同,但是一样可以达到目的。此外,本文中涉及虚拟机的问题也将与之不同,如在 VirtualBox 的安装配置过程中遇到问题还请查阅其他文章。
虚拟机配置
新建虚拟机
首先打开 VMWare Workstation,逐步进行以下流程:
- 点击菜单栏文件
- 新建虚拟机
- 选择 “典型(推荐)”
- 安装程序光盘映像文件,选择下载好的 CentOS 镜像文件
- 修改虚拟机名字(这一步是为了方便管理虚拟机集群,修改名称诸如
hadoop101之类易于分辨的皆可) - 往后一直默认确认,直到虚拟机创建完毕
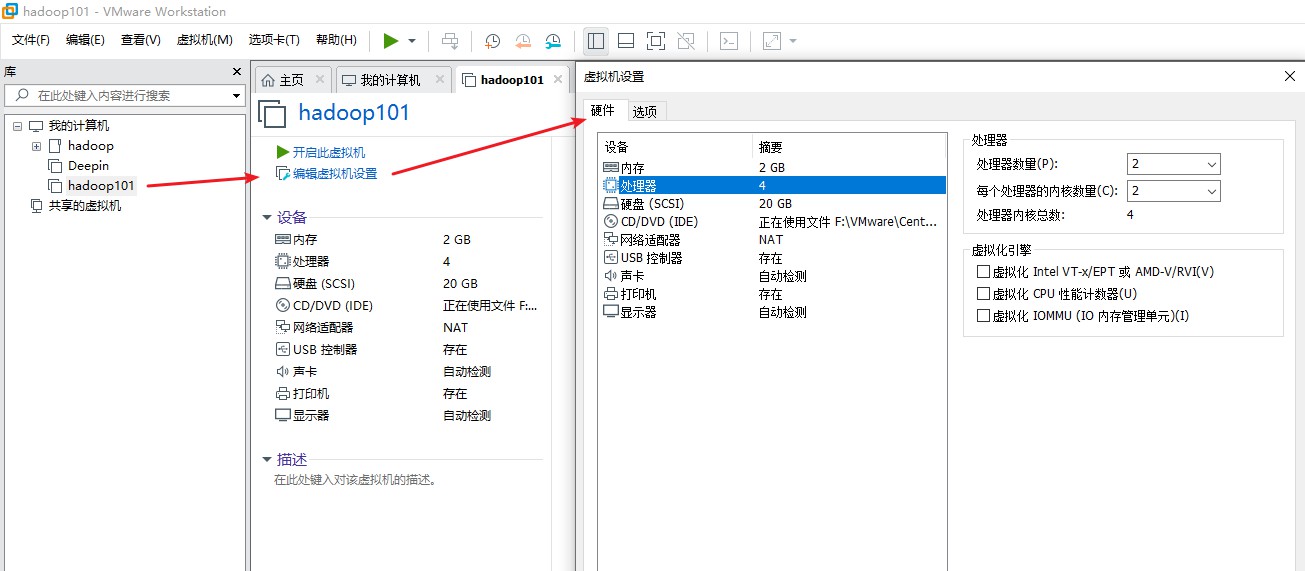
接着需要修改虚拟机配置,基本配置要求如下:
- 硬盘: 20G(视自己硬盘空间而定,默认最低为 20G,后续不够还可以手动扩容)
- 内存: 2G(一般 2G 就够了)
- 处理器: 2 x 2 (即处理器数量和每个处理器的内核数量为 2 x 2,处理器内核总数为 4,如果还需要更高,需要查看自己CPU的个数与核数,处理器总核数不能超过本机上限)
- 网络适配器: NAT 模式(VMware 默认配置)
配置虚拟机
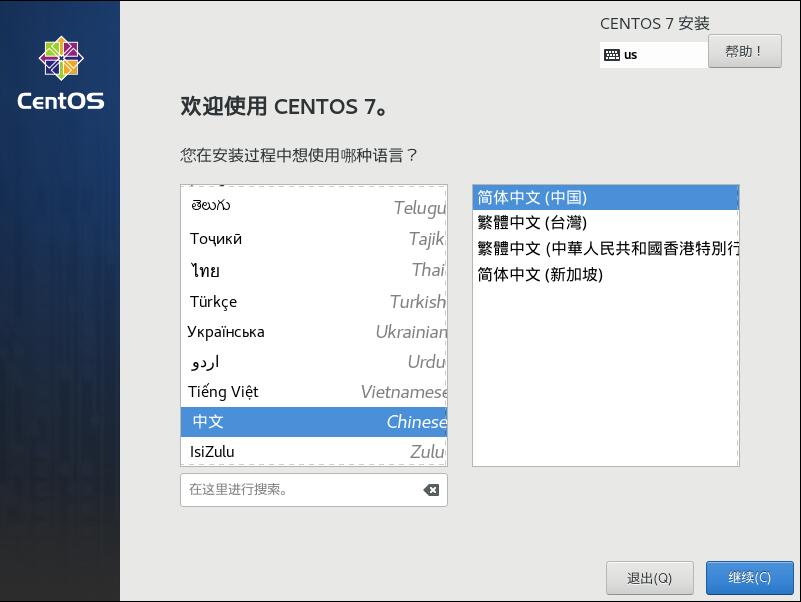
确认后即可点击 “开启此虚拟机” 进行虚拟机的启动项配置,语言设置选择中文
确认后进入 “安装信息摘要”,先配置 “安装位置”
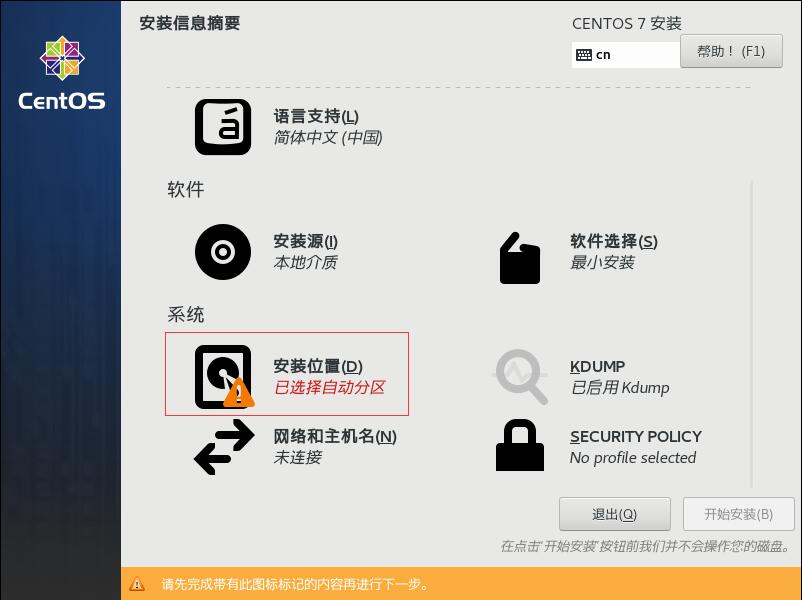
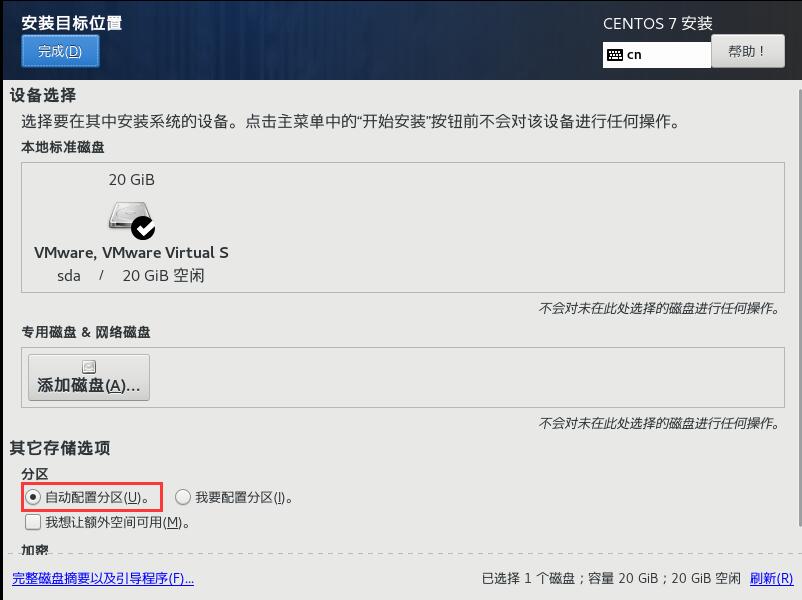
这里为了方便,我选择了 “自动配置分区”。点击 “完成”,回到 “安装信息摘要界面” 后,再点击 “网络和主机名”,打开以太网,点击 “完成”
继续下一步
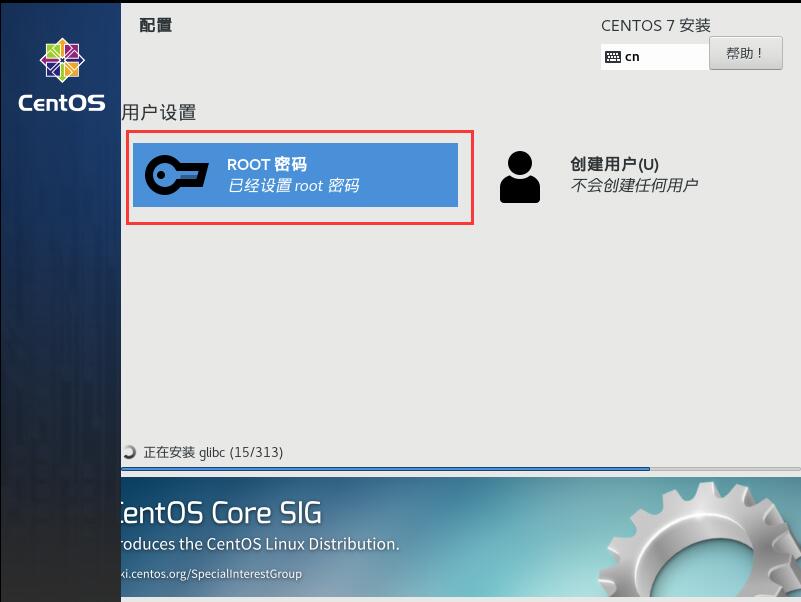
这里要为root配置密码,等会登陆后需要用到,暂时可以不用创建用户。稍等片刻,安装完成后,选择 “重启”。
重启后会看到终端交互界面,输入root和密码即可登录成功
值得注意的是,在分布式集群的使用过程中,是不需要图形界面的,全程会使用 Xshell 这类远程终端工具来远程链接操作集群的系统,文件传输可以使用 Xftp 来完成,也可以使用其他类似的工具,比如 SecureCRT。当然,如果不习惯无操作界面的系统或者其他原因需要 GUI,那么可以在 CentOS 启动项配置过程中的 安装信息摘要 -> 软件 -> 软件选择 中选择自己需要的组件,不过使用默认的 “最小安装” 才是符合实际开发场景的。(GUI 安装选项不是本文重点并且也不需要,可以自行查阅其他文章)
获取IP及关闭防火墙
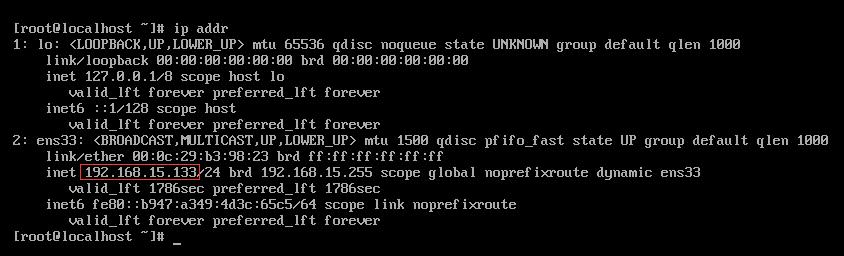
紧接着输入 ip addr 获取本机的 IP 地址,当然前提是在安装时已经打开了以太网的连接
下一步,我们需要将虚拟机的防火墙关闭,这样主机才能 ping 通虚拟机的 IP。相关操作如下所示:
- 启动防火墙:
systemctl start firewalld.service - 关闭防火墙:
systemctl stop firewalld.service - 重启防火墙:
systemctl restart firewalld.service - 显示防火墙状态:
systemctl status firewalld.service - 禁止防火墙开机自启:
systemctl disable firewalld.service
要注意的是,CentOS 7 的防火墙操作指令与 CentOS 6 的不同,如果你是 CentOS 6 的操作系统还请自行查阅相关操作。
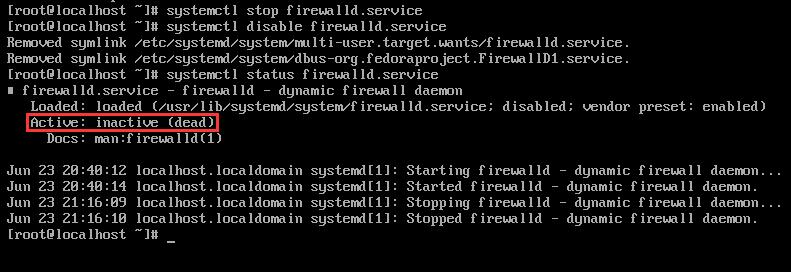
这里我们需要先关闭防火墙,再禁止防火墙开机自启,最后查看一下防火墙状态,出现如下信息则表示防火墙已关闭。
接着主机可以尝试 ping 一下虚拟机的 IP,如果能 ping 通则说明没有问题。
配置静态IP
首先在控制台输入 vi /etc/sysconfig/network-scripts/ifcfg-eth0
输入如下内容
1 | DEVICE=eth0 |
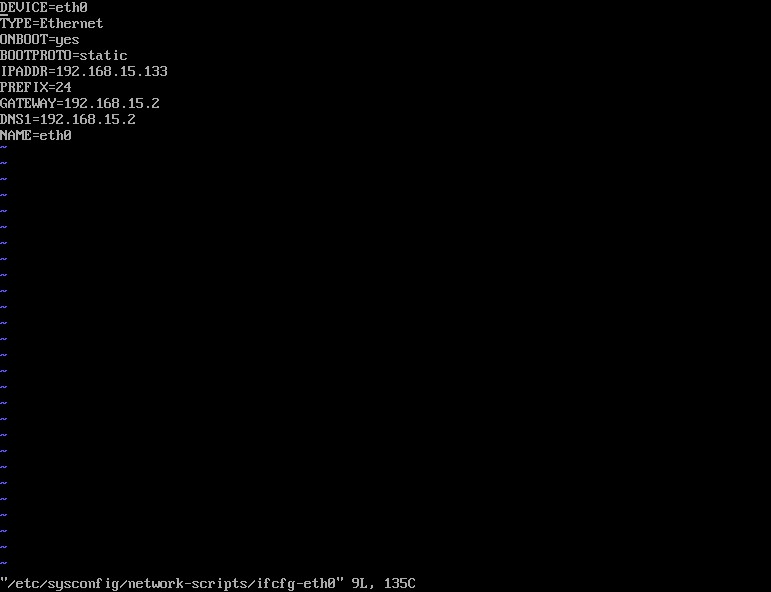
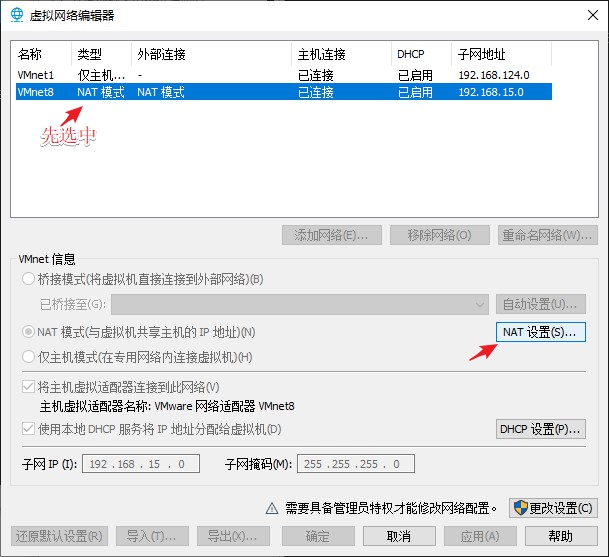
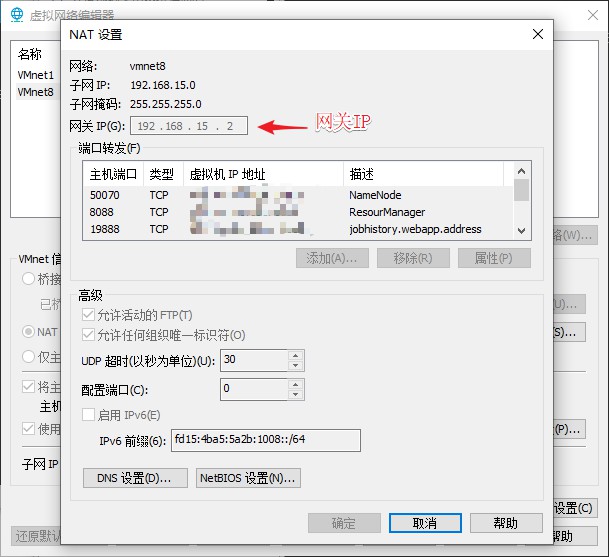
注意 IPADDR 是该台虚拟机的 IP 地址,所以要与你上一步获取到的 IP 地址相一致。此外,对于 GATEWAY 的值,需要查看当前虚拟机的网关,并与之保持一致,DNS1 的值与 GATEWAY 的值相同即可。获取步骤如下
修改主机名
接下来修改主机名,这样做是为了在打开多个系统的终端时,可以分得清对应的是哪个。输入 vi /etc/sysconfig/network,输入如下内容(主机名为 hadoop101),保存之后,重启即可看到主机名已经修改。
1 | NETWORKING=yes |
创建一个一般用户
如果是在自己安装的虚拟机上操作,为了省事可以省略这一步,但是实际操作过程中,是不建议直接使用 root 用户进行操作的。主要原因在于 root 的权限过大,如果在 root 权限下进行了误操作,那么造成的损失会非常大,此外从安全的角度考虑,以 root 身份运行的程序被攻击时,就会直接获取到 root 的密码,其后果也是不堪设想的。对于开发人员来说,普通用户的权限也能够满足绝大部分需求,而且对于有多种用途的 linux 来说,只有一个 root 账号是不便于管理的。因此,本文还是建议按照步骤执行,不要省略这一步。
创建新用户的方式很简单,比如创建一个名为 inno 的用户(用户名请自行替换):
1 | 创建新用户,用户名为 inno,请自行替换 |
可以通过 ll /home 看到刚才创建的用户目录,此时的用户权限较低,为了之后的操作方便,先为新创建的用户赋予 root 权限
为新建用户赋予 root 权限
步骤如下:
- 使用命令
chmod -v u+w /etc/sudoers设置 sudoers 文件权限为可读写 - 使用命令
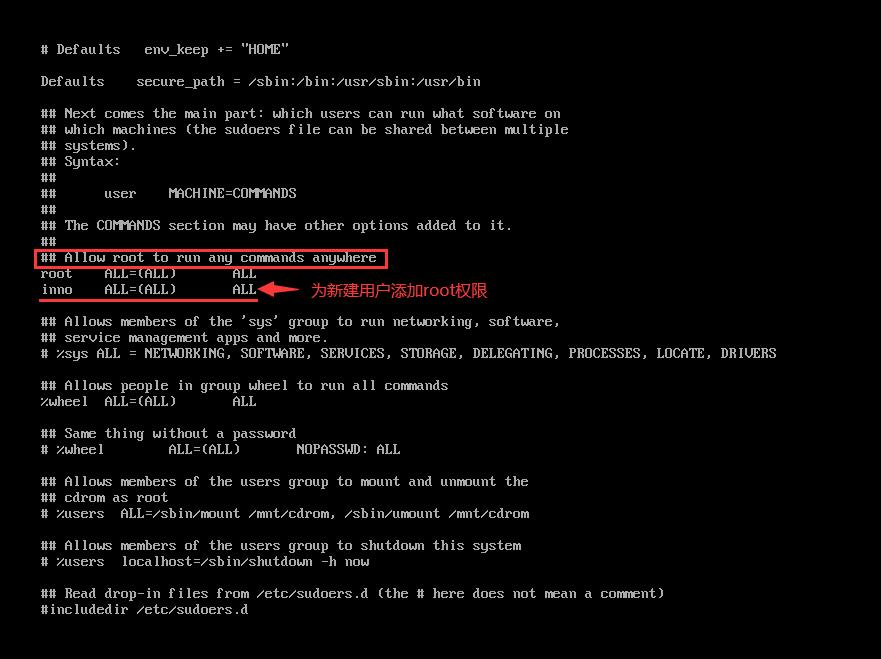
vi /etc/sudoers编辑 sudoers 文件 - 找到
root ALL=(ALL) ALL这一行并在下一行添加新建的用户名,如下:- 添加该行后就可以使用 sudo 行使 root 权限
inno ALL=(ALL) ALL - 若想在使用 sudo 时不输入密码,则可更改为
inno ALL=(ALL) NOPASSWD: ALL - 保存退出
- 添加该行后就可以使用 sudo 行使 root 权限
- 使用命令
chmod -v u-w /etc/sudoers删除 sudoers 写权限
使用命令 su inno,切换到 inno 用户下,测试一下 sudo ls,如果没有报错,则说明配置成功。
创建统一管理压缩包和解压文件的文件夹
在 /opt 下创建 module、software 文件夹,并修改两个文件夹的所有者
1 | sudo mkdir /opt/module |
之后压缩包会统一放在 /opt/software 目录下,解压后的文件会放在 /opt/module 目录下
克隆虚拟机
因为最终的目的是使用多台虚拟机形成一个小集群,所以上面的基本操作是适用于往后所有用作集群的虚拟机的,因此,我们需要在上述操作都完成后,为虚拟机新建一个节点,这样在之后克隆虚拟机时就可以从当前节点克隆,操作流程如下
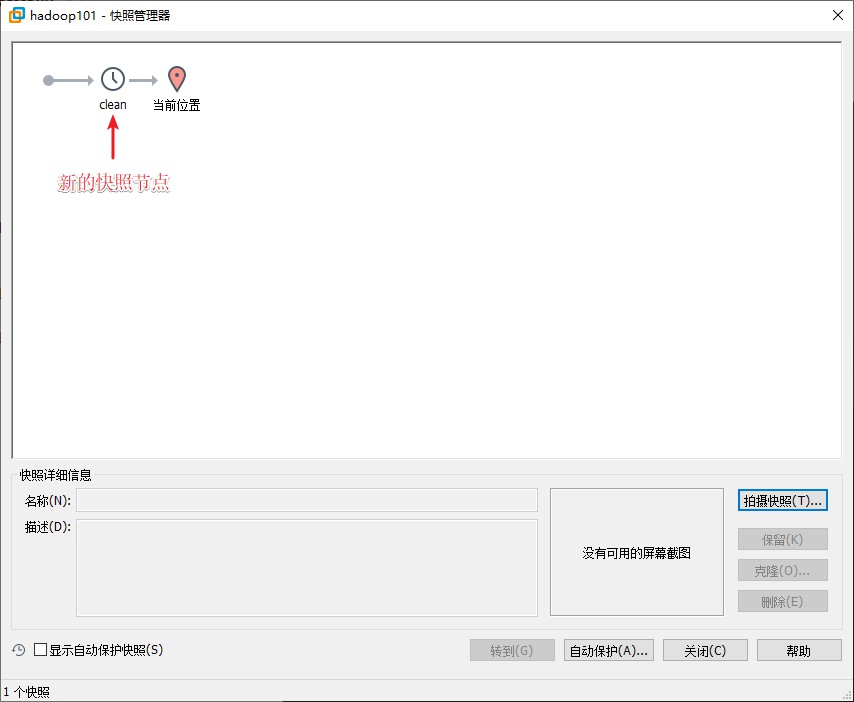
注意,克隆操作需要关闭当前运行的虚拟机后才能运行
Q: 为什么我们要从一个干净的 Linux 虚拟机开始克隆?可否在配置完一台虚拟机的 Hadoop 环境后再进行克隆?
A: 按理说是可以的,特别是对于在自己本机上用虚拟机搭建的分布式环境来说,这样在配置好一台 Hadoop 环境后再克隆可以方便很多。但是在实际开发过程中,往往用的不会是虚拟机,而是在服务器上,这就没有办法进行克隆操作了,因此学习如何远程同步多台虚拟机的配置环境是很有必要的。
选择 “clean” 节点,点击右下的 “克隆” 按钮,再克隆两台虚拟机,并且虚拟机名字分别为 hadoop102 和 hadoop103。
注意 对于新克隆的虚拟机,还需要执行两个步骤,参照 配置静态IP 和 修改主机名 这两步的操作,分别设置对应的静态 IP 地址和网关,以及修改新克隆的两台虚拟机的主机名为 hadoop102 和 hadoop103,然后重启即可。
配置 hosts
将三台虚拟机都打开并登陆后,输入 ip addr 查看各自的 IP 地址,本文中三台虚拟机的 IP 地址和主机名的映射关系如下:
1 | 192.168.15.133 hadoop101 |
接着需要把这些内容复制到每台虚拟机的 host 文件中,在每台虚拟机终端中输入命令 vi /etc/hosts ,将内容复制进去即可。
如果不想挨个操作,可以在修改完 hadoop101 的 /etc/hosts 文件后,就在 hadoop101 这台虚拟机的终端上使用命令拷贝到另外两台虚拟机的对应位置上(IP 地址为另外两台虚拟机的IP地址)
1 | scp /etc/hosts root@192.168.15.134:/etc/ |
注意,还需要在你 Windows 的 hosts 文件中配置以上 IP 映射,否则后面无法通过主机名链接到 HDFS。Windows 的 hosts 文件路径为 C:\Windows\System32\drivers\etc\HOSTS,以管理员身份打开,并将上面的 IP 地址映射添加到文件末尾后保存(Mac OS 的添加方式自行查阅)。
使用 Xshell 远程访问虚拟机
实际开发环境中,是没法直接去操作节点的,这时候就需要使用 Xshell 这类远程终端工具来访问。在自己的电脑上操作时也很方便,只要第一次连接成功后,之后每次只需打开虚拟机就可以放到后台了,直接操作终端界面会比在虚拟机之间来回切换方便很多。同样的还有一款 Xftp 文件传输工具,我们也可以用类似的方式通过远程连接来往节点传送文件。对于 Xshell 连接步骤如下
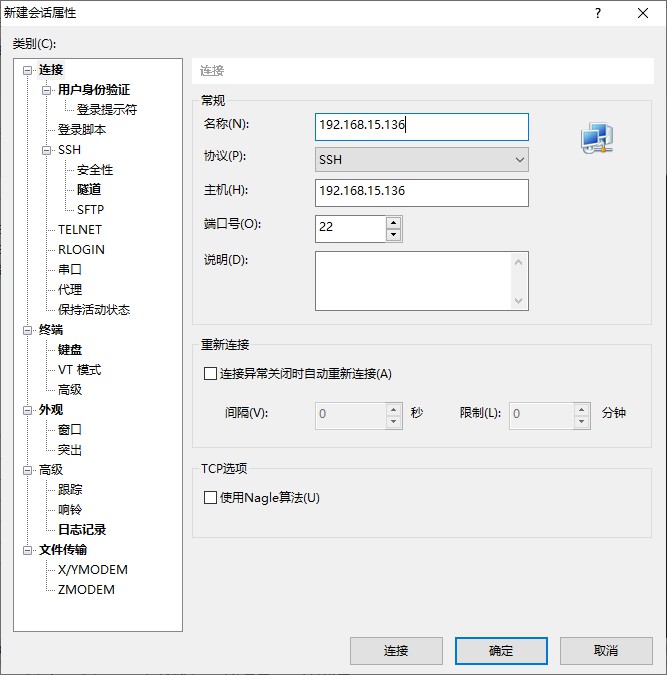
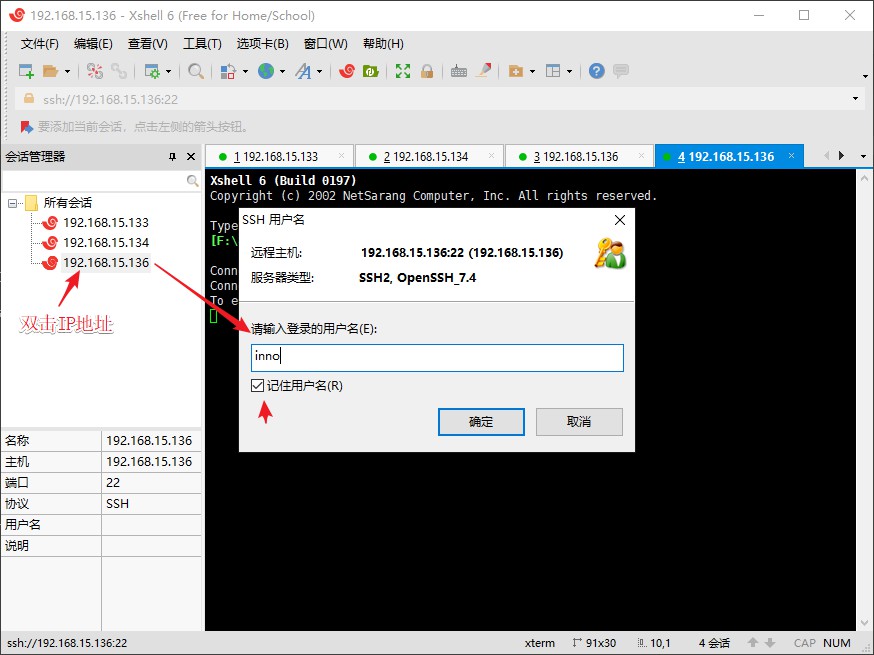
如果是第一次连接,则会提示是否保存主机密钥,点击保存即可。
Xftp 的连接方式类似,新建连接,然后输入 IP 地址,之后选择 IP 地址后再输入用户名和密码即可。
之后的所有操作都将通过 Xshell 来完成,虚拟机只会放到后台运行。
配置ssh免密登录
集群之间的主机需要能够相互进行通信,因此配置 ssh 免密登录十分重要。先在 hadoop101 上输入以下命令:
1 | ssh-keygen -t rsa |
然后可以一直敲回车直到结束。接着拷贝生成的公钥到另外两台虚拟机上,在 hadoop101 上输入以下命令:
1 | ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop102 |
这样就将 hadoop101 的 ssh 密钥拷贝到了 hadoop102 和 hadoop103 上。另外两台虚拟机也需要执行上面两步,要注意修改要拷贝到的虚拟机的主机名(对于 haoop102 的密钥,就是要拷贝到 hadoop101 和 hadoop103 上)。
然后测试一下是否可以连接成功,比如在 hadoop101 上输入 ssh hadoop102,如果出现如下类似结果即表示成功

Hadoop 完全分布式配置
集群部署规划及资源准备
| hadoop101 | hadoop102 | hadoop103 | |
|---|---|---|---|
| HDFS | DataNode NameNode |
DataNode | DataNode SecondaryNameNode |
| YARN | NodeManager | NodeManager ResourceManager |
NodeManager |
因为资源有限,所以在该集群中只是用了三台虚拟机,hadoop101 既是 HDFS 集群的主机(包含NameNode)也是 HDFS 集群的从机(连同另外两台都包含 DataNode);hadoop102 既是 YARN 集群的主机(包含 ResourceManager)也是 YARN 集群的从机(连同另外两台)。
接下来开始按照集群部署规划开始安装配置,在此之前,还需要先将下载好的 JDK 和 Hadoop 压缩包通过 Xftp 传入到 hadoop101 上。打开 Xftp 然后确保已成功连接上 hadoop101,在左边的 Windows 文件树中找到 JDK 和 Hadoop 压缩包,然后再在右边找到虚拟机的 /opt/software 目录,直接将左边的文件拖到到右边的文件夹即可
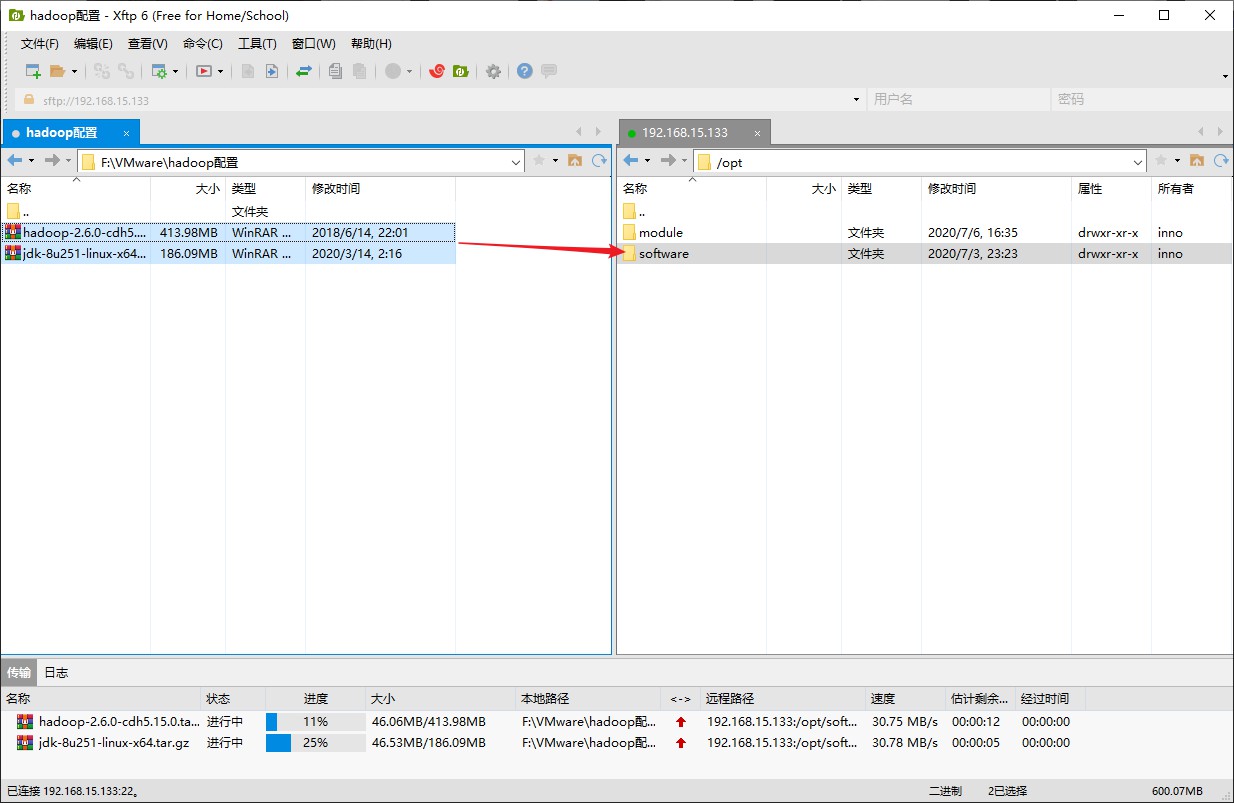
往后的操作会先在 hadoop101 上进行资源解压和配置,然后再利用同步的方式,将解压文件和配置环境同步到另外两台虚拟机上。
安装并配置 JDK
如果 CentOS 7 安装的是带 GUI 的版本,那么系统会自带 Java,因此还需要先删除系统自带的 JDK 再安装自己的JDK,删除方法自行查阅。
先解压 JDK 到 /opt/module 目录下
1 | [inno@hadoop101 ~]$ cd /opt/software/ |
再来配置 JDK 环境变量,这里先获取 JDK 的路径,以便后面的操作
1 | [inno@hadoop101 jdk1.8.0_251]$ pwd |
接着输入 sudo vi /etc/profile 打开 /etc/profile 文件,并在末尾添加 JDK 的环境变量
1 | JAVA_HOME |
保存退出后输入 source /etc/profile 让配置文件生效,测试一下,若出现如下信息则表示 JDK 配置成功
1 | [inno@hadoop101 jdk1.8.0_251]$ java -version |
接着另外两台虚拟机也可以按照上述步骤手动安装,也可以使用以下命令同步到另外两台虚拟机
1 | sudo rsync -av /opt/module/jdk1.8.0_251 hadoop102:/opt/module/ |
rsync 是一种远程同步工具,具有速度快、避免复制相同内容和支持符号链接的优点。相比于上面使用过的 scp,用 rsync 做文件的复制要比 scp 的速度快,并且 rsync 只对差异文件做更新而 scp 是把所有文件都复制过去。这在之后会有很多的用途。在使用之前还需要在每台虚拟机上运行如下代码快速安装
1 | sudo yum install rsync -y |
注意 将 JDK 和 /etc/profile 文件同步完成后,还需要到另外两台虚拟机上执行 source /etc/profile 命令,使配置生效,然后再测试一下 java -version,确保输出正确信息,确认无误后方可进行接下来的操作。
安装并配置 Hadoop
解压并配置环境变量
同样的,先到 hadoop101 上的 /opt/software 找到 Hadoop 的压缩包,解压到 /opt/module 目录下
1 | [inno@hadoop101 ~]$ cd /opt/software/ |
接着获取 hadoop 解压后的文件路径,以便等下配置 Hadoop 的环境变量
1 | [inno@hadoop101 hadoop-2.6.0-cdh5.15.0]$ pwd |
接着输入 sudo vi /etc/profile 打开 /etc/profile 文件,并在末尾添加 Hadoop 的环境变量
1 | HADOOP_HOME |
保存退出后输入 source /etc/profile 让配置文件生效,测试一下,若出现如下信息则表示 Hadoop 配置成功
1 | [inno@hadoop101 hadoop-2.6.0-cdh5.15.0]$ hadoop version |
Hadoop的目录结构
这里临时阐述一下 Hadoop 的目录结构,是为了之后配置一些文件的时候,能大致明白其作用
bin目录:存放对 Hadoop 相关服务(HDFS,YARN)进行操作的脚本etc目录:Hadoop 的配置文件目录,存放 Hadoop 的配置文件lib目录:存放 Hadoop 的本地库(对数据进行压缩解压缩功能)sbin目录:存放启动或停止 Hadoop 相关服务的脚本share目录:存放Hadoop的依赖 jar 包、文档、和官方案例
只后要配置的所有文件的位置,都在你 hadoop 解压目录下的 etc/hadoop 目录下
配置集群
核心文件配置
配置 core-site.xml,输入 vi core-site.xml,并在文件中添加如下内容
1 | <!-- 指定HDFS中NameNode的地址 --> |
HDFS 文件配置
配置 hadoop-env.sh,输入 vi hadoop-env.sh,,找到 # The java implementation to use. 这一行
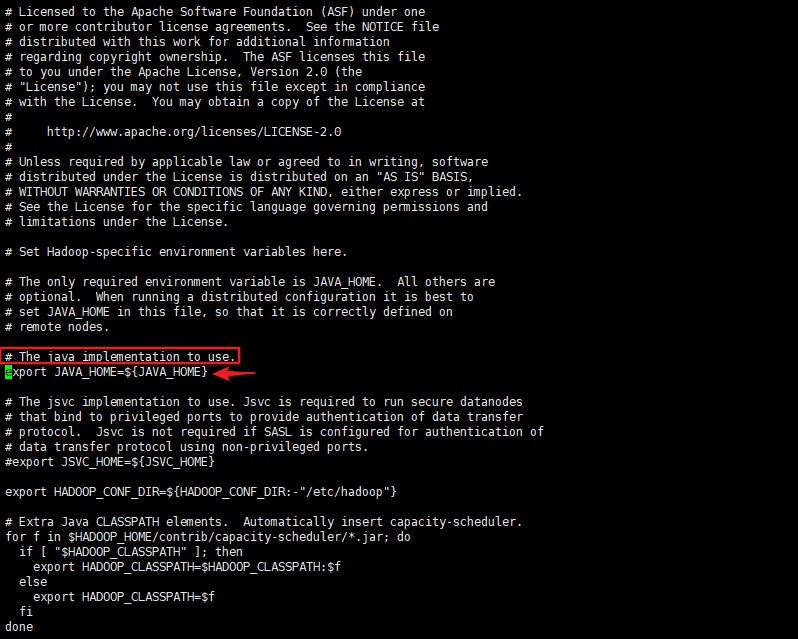
将下面一行的 JAVA_HOME 修改为自己的
1 | export JAVA_HOME=/opt/module/jdk1.8.0_251 |
配置 hdfs-site.xml,输入 vi hdfs-site.xml,并在文件中添加如下内容
1 | <!-- 指定HFDS副本的数量 --> |
YARN 文件配置
配置 yarn-env.sh,输入 vi yarn-env.sh,找到 # some Java parameters 这一行
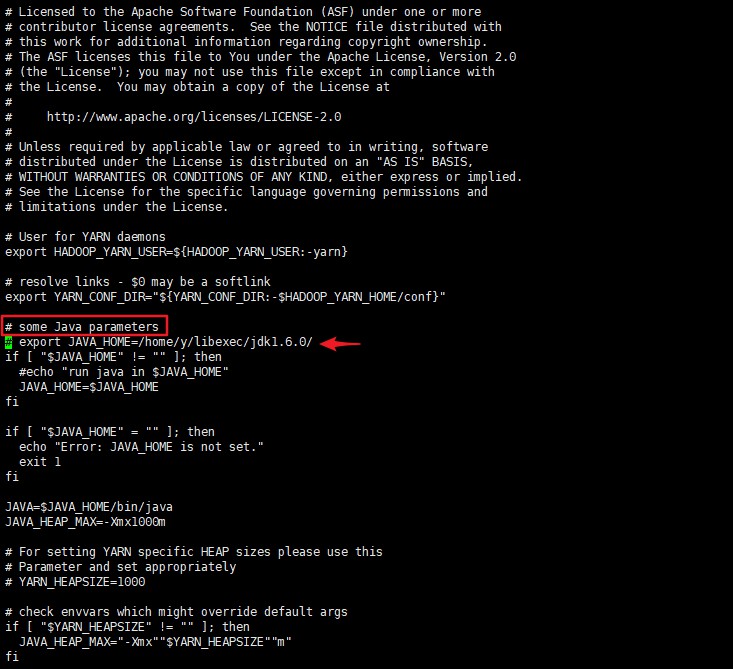
取消在这一行下面的 JAVA_HOME 注释,并修改为自己的 JAVA_HOME
1 | export JAVA_HOME=/opt/module/jdk1.8.0_251 |
配置 yarn-site.xml,输入 vi yarn-site.xml,并在文件中添加如下内容
1 | <!-- Reducer获取数据的方式 --> |
MapReduce 文件配置
配置 mapred-env.sh,输入 vi mapred-env.sh,找到被注释的 # export JAVA_HOME=...,
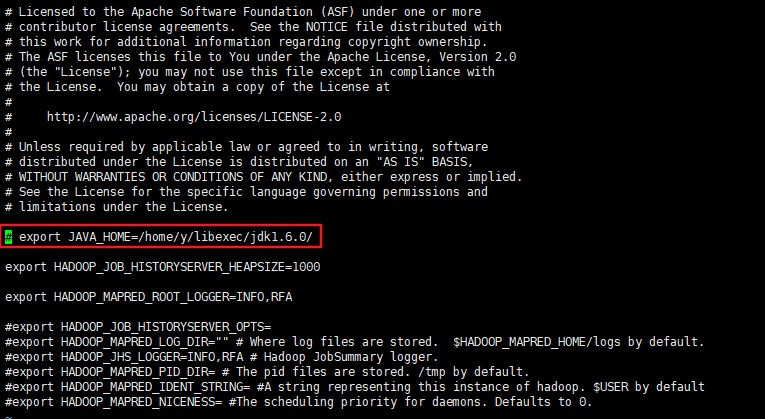
取消该注释,并修改为自己的 JAVA_HOME
1 | export JAVA_HOME=/opt/module/jdk1.8.0_251 |
配置 mapred-site.xml,因为一开始是没有该文件的,需要先拷贝 mapred-site.xml.template 并重命名为 mapred-site.xml
1 | cp mapred-site.xml.template mapred-site.xml |
输入 vi mapred-site.xml,并在文件中添加如下内容
1 | <!-- 指定MR运行在Yarn上 --> |
配置 slaves
配置从节点的主机名,如果有按照之前的步骤在 /etc/hosts 文件中做了 IP 地址和主机名的映射,那么就可以直接使用主机名,否则就需要写对应的 IP 地址
输入 vi slaves,并在文件中添加如下内容
1 | hadoop101 |
注意 文件中添加的内容结尾不允许有空格,并且文件中不允许有空行。
同步虚拟机文件及配置环境
1 | sudo rsync -av /opt/module/hadoop-2.6.0-cdh5.15.0 hadoop102:/opt/module/ |
注意 在完成了同步操作后,还需要在各台虚拟机上执行 source /etc/profile 使配置生效。
启动集群
格式化 NameNode
如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
1 | hdfs namenode -format |
注意 NameNode 只在第一次启动时需要格式化,往后非必要的情况下都不需要格式化,因为频繁的格式化会导致出现一些意想不到的问题,比如找不到 DataNode 等。
启动HDFS和YARN
- 先在
hadoop101上启动 HFDS,使用脚本命令start-dfs.sh - 再在
hadoop102(包含 ResourceManager) 上启动 YARN,使用脚本命令start-yarn.sh
注意 若 NameNode 和 ResourceMange 不是同一台机器,则不能在 NameNode 上启动 YARN,应该在 ResouceManager 所在的机器上启动 YARN。
接下来使用 jps 命令分别查看一下三台虚拟机的运行情况
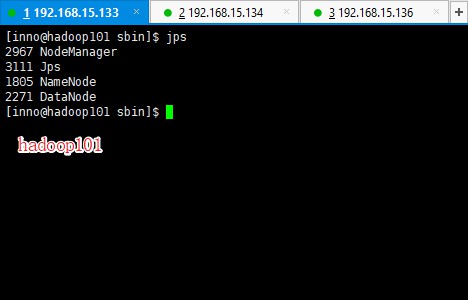
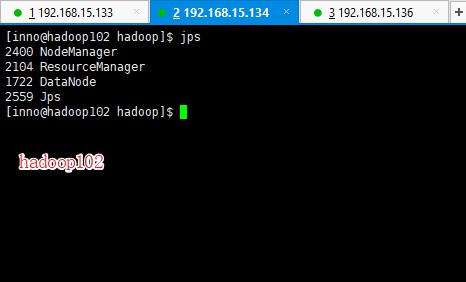
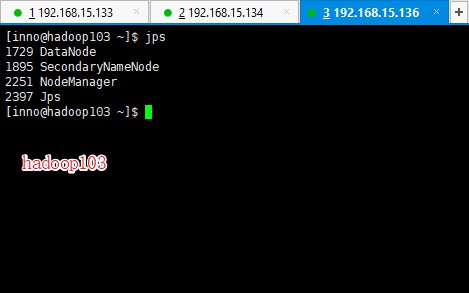
结果与之前的集群部署规划相符合。至此,Hadoop 分布式集群基本部署完成,再来看一下控制台的情况,以下操作在自己本机(Windows / Mac OS)的浏览器中操作
输入 haoop101:50070 查看 HDFS 的运行情况:
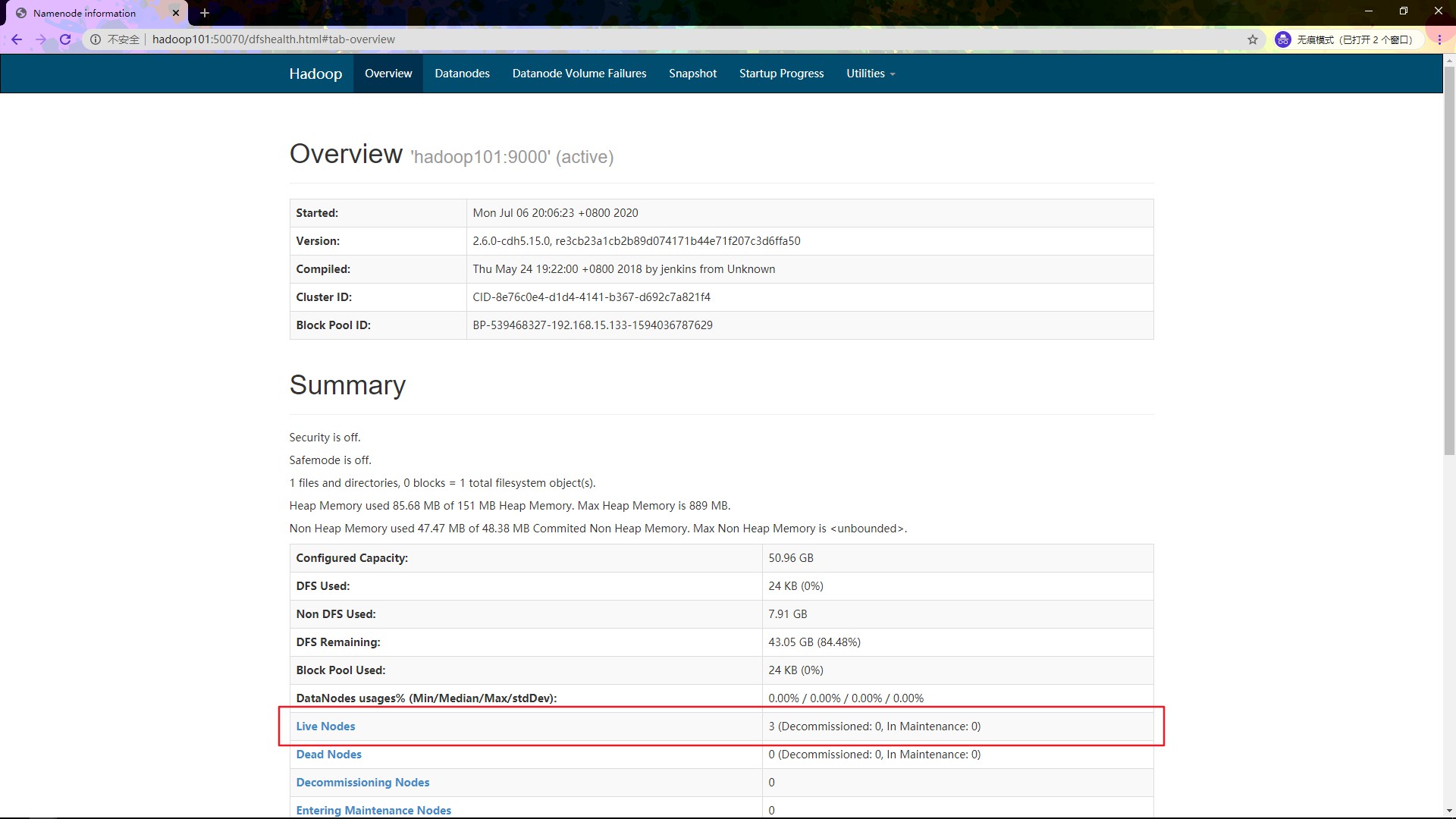
再点击头部的 Datanodes 查看 DataNode 的情况
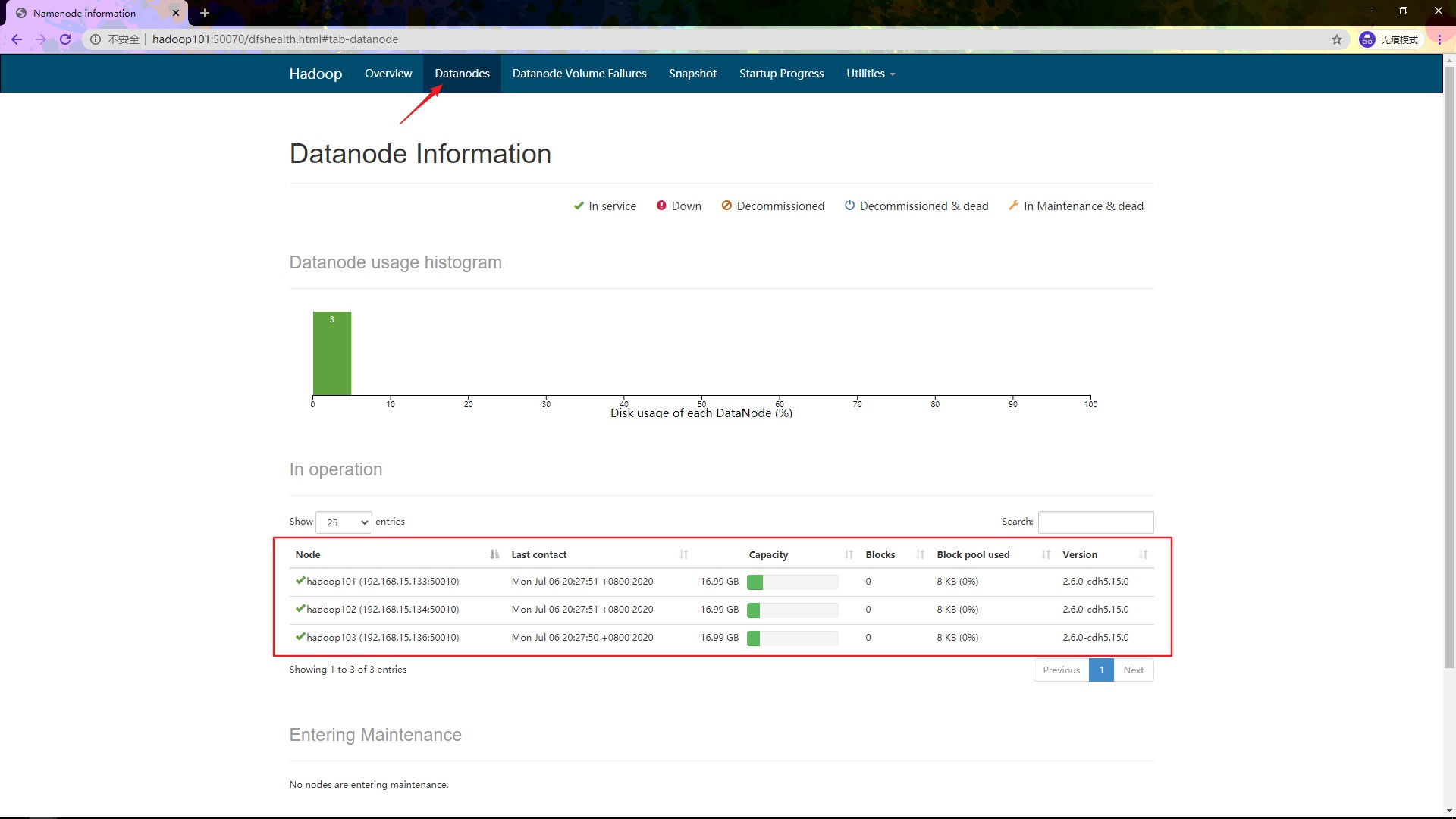
可以发现 3 台 DataNode 都已经运行起来了。接着输入 hadoop102:8088 查看 YARN 的运行情况:
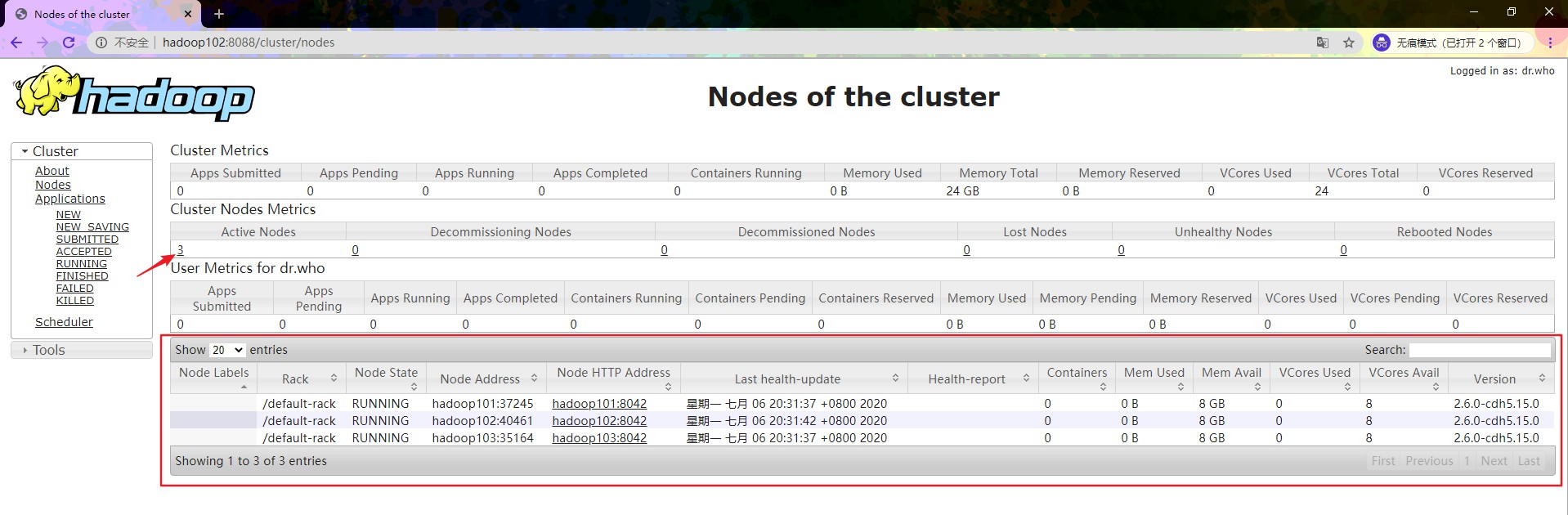
点击 Active Nodes 下的数字 3,还可以看到红框内存活着的三台 DataNode 的信息
启动历史服务器
因为之前已经在 YARN文件配置 和 MapReduce文件配置 这一步中配置过历史服务器了,所以这里可以直接在 hadoop101 上使用命令启动历史服务器
1 | mr-jobhistory-daemon.sh start historyserver |
使用 jps 查看启动情况
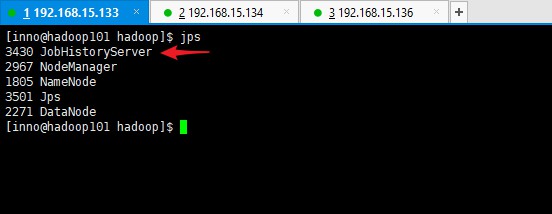
配置历史服务器的目的是为了方便查看程序的历史运行情况。
运行官方示例
经过以上的铺垫,下面就可以使用官方示例查看一下实际的运行效果
在主机 hadoop101 的 /opt/module/hadoop-2.6.0-cdh5.15.0 目录下,执行如下命令,回车便可看到运行结果
1 | [inno@hadoop101 hadoop-2.6.0-cdh5.15.0]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.15.0.jar pi 3 4 |
看一下控制台的情况,浏览器输入 hadoop102:8088,可以看到官方示例已经运行完成。因为上一步已经配置过了历史服务器,正好可以看一下官方示例的运行过程中,产生的日志,查看步骤如下
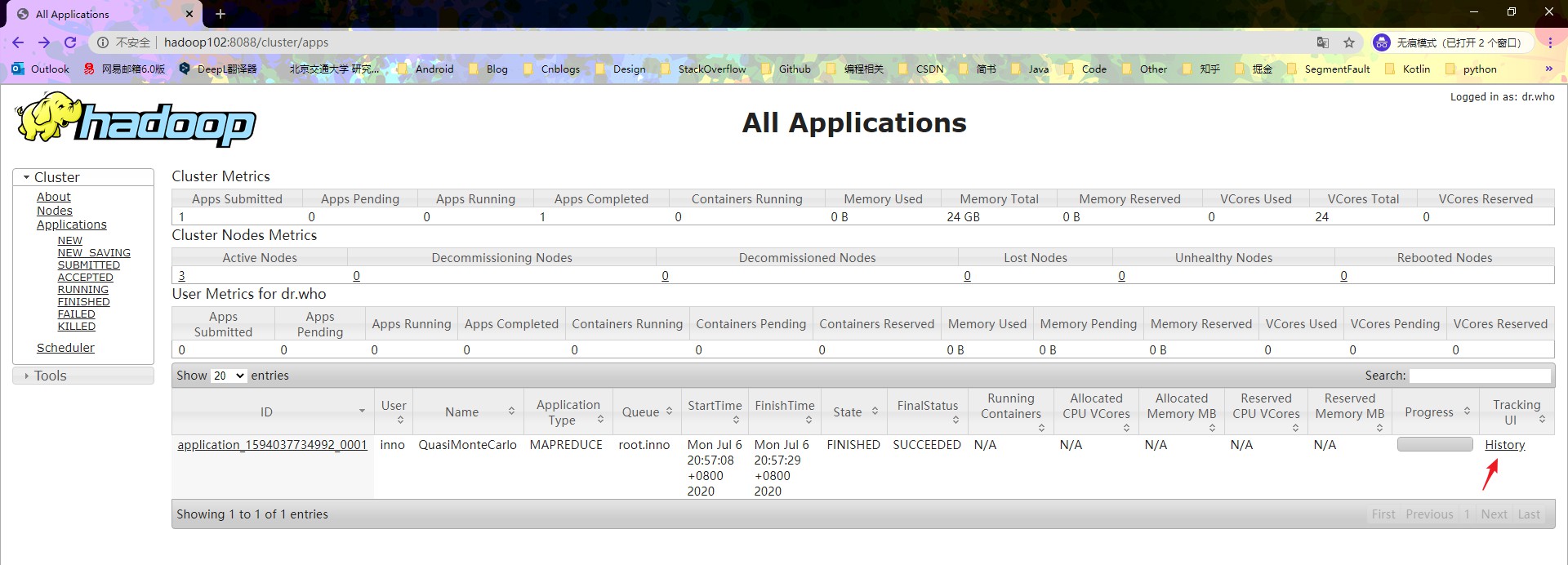
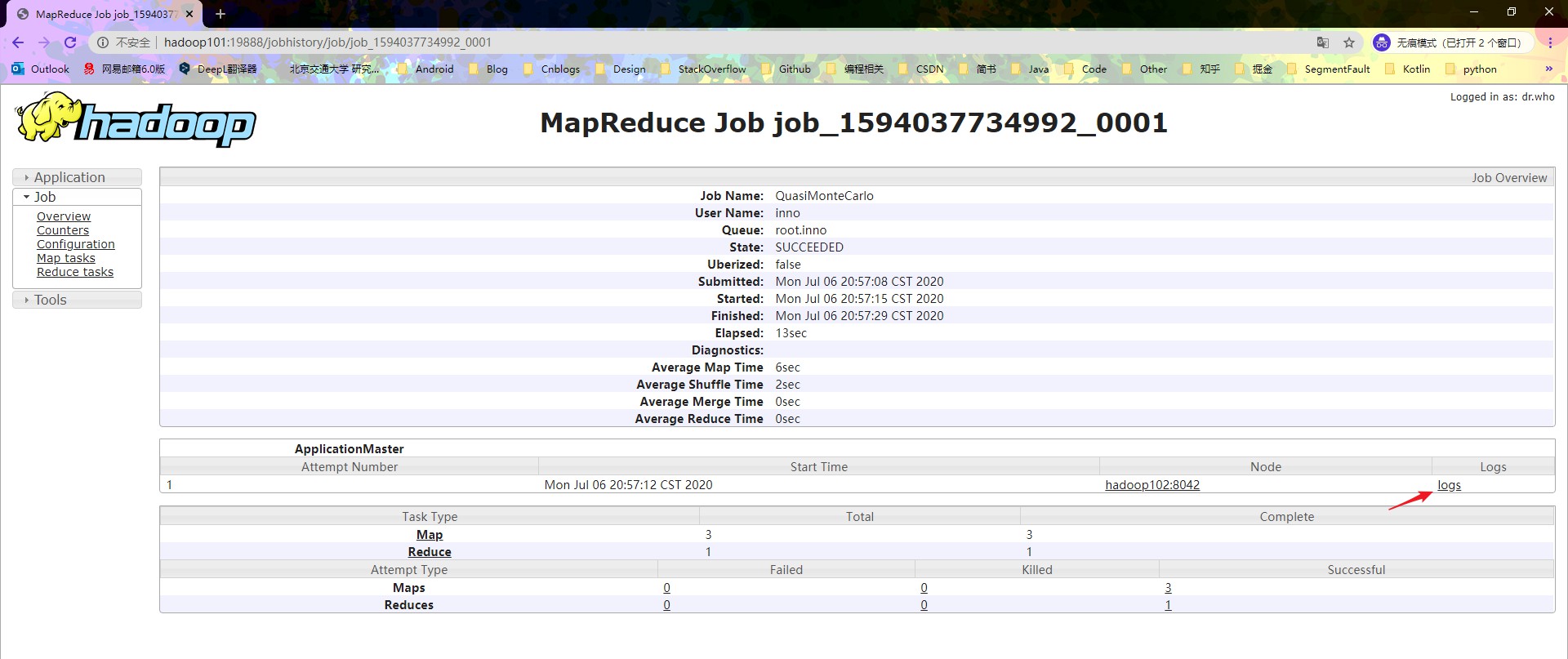
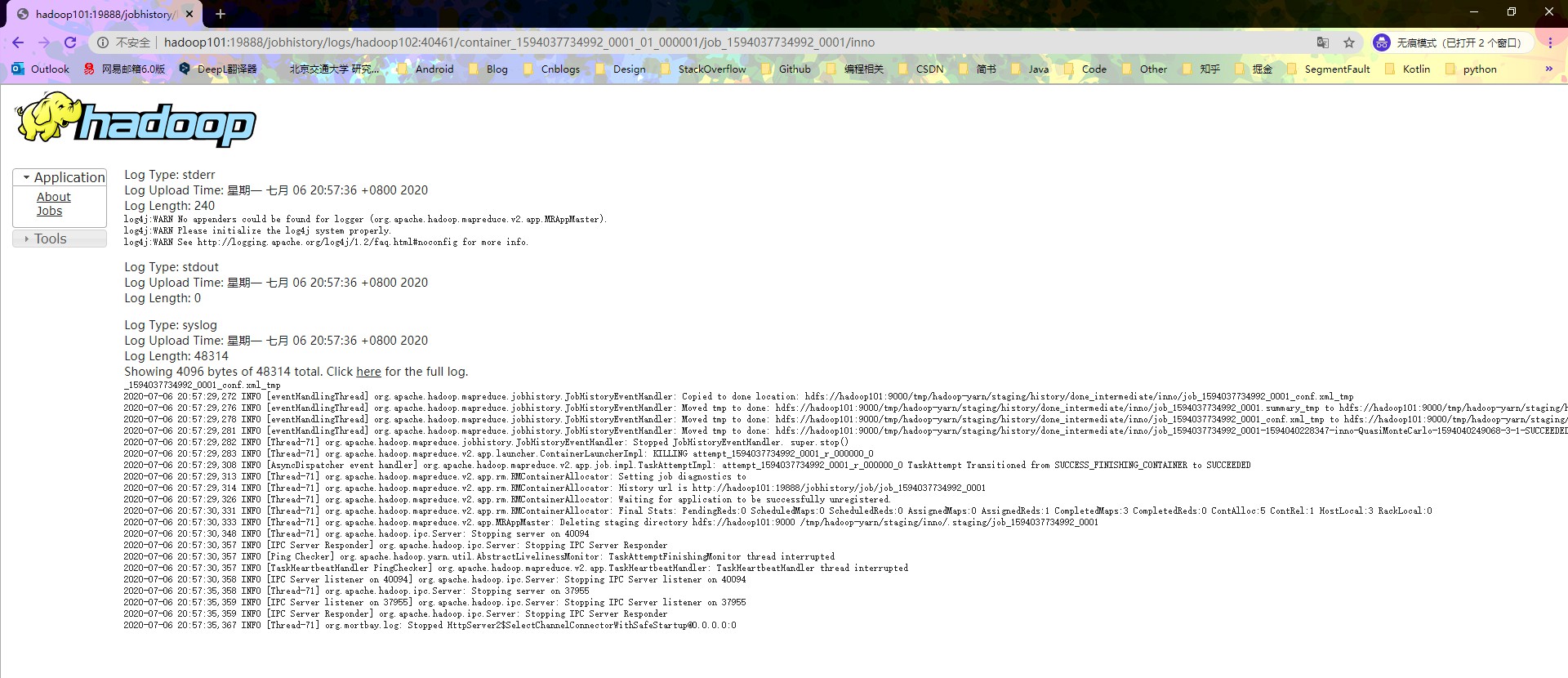
如果我们的 MapReduce 程序出现了错误,那么查看 Log 文件可以很好的帮助我们解决问题。
停止集群
当不需要运行集群的时候,要注意千万不能直接关闭虚拟机,一定要先停止集群的运行,再关闭虚拟机,否则会造成很多想不到的结果。
- 停止历史服务器:
mr-jobhistory-daemon.sh stop historyserver - 停止YARN:
stop-yarn.sh - 停止HDFS:
top-dfs.sh
其他
集群时间同步
经过之前的步骤,Hadoop 完全分布式集群已经配置完成了,所以这一步的集群时间同步与 Hadoop 集群的关系不是特别大。所谓的集群时间同步,就是为了让三台服务器的时间取得一致(仅仅只是保持一致,而非保证时间正确),这么做的目的是因为在之后使用集群的过程中,比如使用 HBase 的时候,对主机和从机的时间同步性要求很高。虽然说集群时间同步的配置与否并不影响 Hadoop,但是在之后的使用过程中,还是需要有这么一个步骤,因此这里建议还是顺便配置一下。
时间同步的原理也很简单:找一个机器,作为时间服务器,集群中其它所有的机器与这台机器的时间进行定时的同步,比如,每隔十分钟同步一次时间。
因为时间同步服务依赖于 NTP 服务,所以首先应该查一下系统是否具有 NTP 服务。注意,以下操作都需要在 root 用户下执行,因此在执行所有操作前进行切换 ,使用命令 su root ,如果不切换那么就需要每条命令之前加上 sudo。
检查NTP服务是否存在
首先,检查 NTP 是否安装 rpm -qa|grep ntp,如果没有输出任何信息,则表示系统没有 NTP 服务,那么输入 yum install ntp 安装一下即可。然后再输入 rpm -qa|grep ntp 检查一下是否有输入,如果出现如下信息,则表示 NTP 服务已存在

检查NTPD服务是否开启
输入 service ntpd status,如果出现如下信息则表示服务未开启

如果显示正在运行,那么需要先将其关闭,否则端口会被占用。关闭的步骤也很简单,依次输入如下两条命令
- 输入
service ntpd stop即关闭 NTP 服务 - 然后
chkconfig ntpd off
注意 以上 检查NTP服务是否存在 和 检查NTP服务是否开启 需要分别在三台虚拟机上执行,往下开始正式的配置。
修改NTP配置文件
我们选择 hadoop101 作为时间服务器,因此这一步的修改配置文件将在 hadoop101 的终端上执行,输入 vi /etc/ntp.conf
- 找到
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap这一行,并取消它的注释 - 找到如下几行并都为其添加注释
1
2
3
4server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst - 在文件末尾添加如下两行(目的是当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
1
2server 127.127.1.0
fudge 127.127.1.0 stratum 10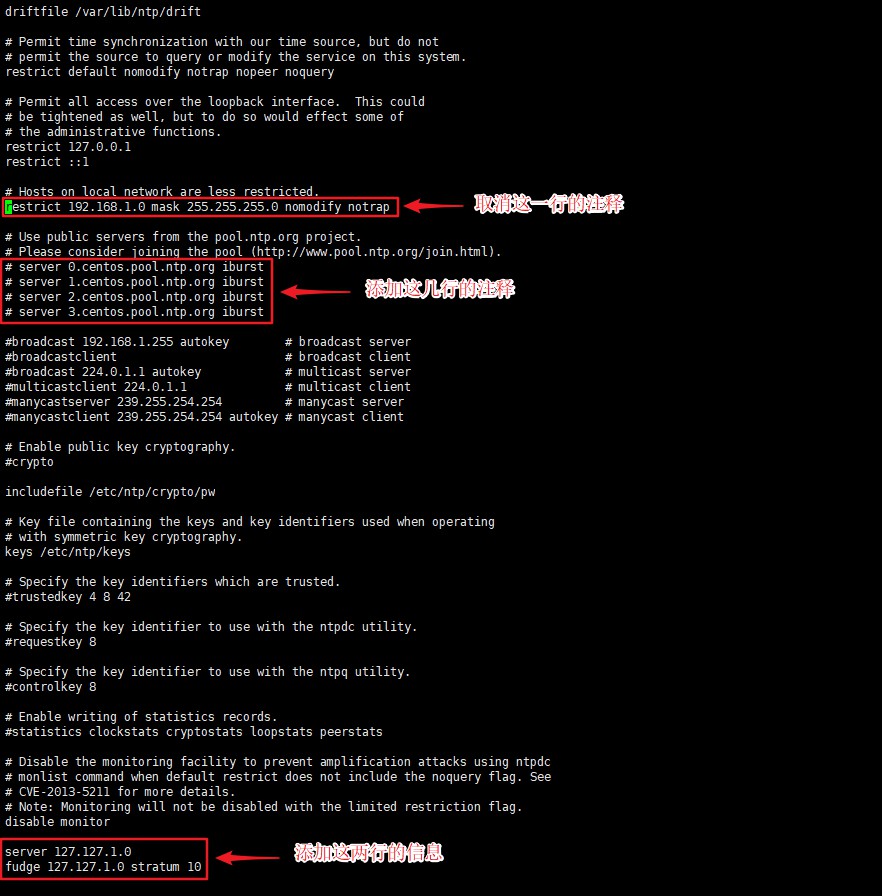
修改/etc/sysconfig/ntpd文件
这一步是为了让硬件时间与系统时间一起同步,输入 vi /etc/sysconfig/ntpd,文件末尾添加如下内容
1 | SYNC_HWCLOCK=yes |
重启NTP服务并设置开机自启
先检查一下 NTPD 服务的状态,输入 service ntpd status,一般来说是停止的,因为没停止是不能修改的,但是操作前进行检查还是有必要的。
- 开启 NTPD 服务
service ntpd start - 设置 NTPD 服务开机自启
chkconfig ntpd on
至此,hadoop101 作为时间服务器已经配置完成。
配置其它机器与时间服务器进行同步
在另外两台虚拟机上,配置 10 分钟与时间服务器同步一次,输入 crontab -e,编写定时任务如下
1 | */10 * * * * /usr/sbin/ntpdate hadoop101 |
这定时任务的意思就是:每隔 10 分钟执行一次 /usr/sbin/ntpdate hadoop101 命令。
至此就完成了集群时间同步的配置。如果想要测试一下,可以修改其他两台机器的时间,比如在另外两台机器的终端中输入 date -s "2020-02-02 20:02:20" 修改一下时间,十分钟后再输入 date 查看时间是否已经恢复。当然为了便于快速看到结果,定时任务的时间间隔可以修改成一分钟(将 10 改为 1 即可)。