Iterator (迭代器模式)
其实在平常的开发当中,迭代器模式是被经常使用的,举个例子,比如使用迭代器遍历结合
/* 创建List容器*/
List<Integer> list = new ArrayList<>();
/* 添加数据*/
for (int i = 0; i < 100; i++) {
list.add(i);
}
/* 迭代容器 */
Iterator<Integer> iterator = list.iterator();
while(iterator.hasNext()) {
System.out.println(iterator.next());
}
如此看来,开发者对于迭代器模式应该还是比较熟悉的,而迭代器的作用也确如其名 ———— 遍历一个容器对象。
下面来看一下迭代器模式UML的类图
Iterator (迭代器模式)的UML类图
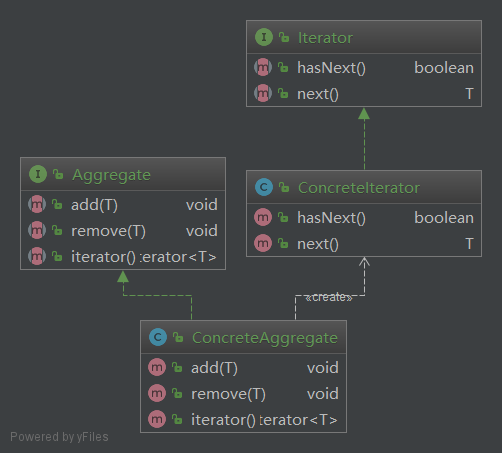
- Aggregate : 容器接口
- ConcreteAggregate : 具体容器类
- Iterator : 迭代器接口
- ConcreteIterator : 具体的迭代器接口
那么迭代器模式在一个自定义的容器中是如何使用的呢?
我们在使用迭代器模式的时候,是先从容器中获得迭代器对象的,当获得迭代器对象后,在利用迭代器的 hasNext() 方法来判断是否有下一个元素,当结果为 true 时,再利用 next() 方法返回下一个数据,以此来达到遍历结合的目的
如果这一块不熟悉,可以看一下下面的例子来加深理解
首先先创建一个 Iterator 接口
public interface Iterator<T> {
boolean hasNext();
T next();
}
这里含有两个方法,分别是用来判断是否有下一个元素的 hasNext() 方法和获取下一个元素的 next() 方法
再创建 Aggregate 接口
public interface Aggregate<T> {
void add(T obj);
void remove(T obj);
Iterator<T> iterator();
}
这里有三个方法,分别是添加元素,删除元素,获取对应的迭代器
然后就可以实现具体的 Aggregate 类 和 对应的具体的 Iterator 类了
具体的 Aggregate 类 -> ConcreteAggregate
public class ConcreteAggregate<T> implements Aggregate<T> {
private List<T> list = new ArrayList<>();
@Override
public void add(T obj) {
list.add(obj);
}
@Override
public void remove(T obj) {
list.remove(obj);
}
@Override
public Iterator<T> iterator() {
return new ConcreteIterator<T>(list);
}
}
具体的 Iterator 类 -> ConcreteIterator
public class ConcreteIterator<T> implements Iterator<T> {
private List<T> list;
private int cursor = 0;
public ConcreteIterator(List<T> list) {
this.list = list;
}
@Override
public boolean hasNext() {
return cursor != list.size();
}
@Override
public T next() {
T obj = null;
if (hasNext()) {
obj = list.get(cursor++);
}
return obj;
}
}
测试如下
Aggregate<String> aggregate = new ConcreteAggregate<>();
aggregate.add("Hello");
aggregate.add("Android");
aggregate.add("Bye");
Iterator<String> iterator = aggregate.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
用户只需要将元素添加进对应的 Aggregate 即可,至于具体的迭代细节不需要考虑,这便是迭代器模式的好处
下面来看一下迭代器模式的简单实现
迭代器模式的简单实现
来一个例子:如果假设现在图书馆新进了一批书,现在你需要遍历查找这些新进的书是否有自己想要的
当然,如果只是创建一个 Book 的实体类,然后再创建一个 Book 类型的 List 集合,然后遍历这个 List 集合,似乎问题并没有那么复杂,但是,在实际开发当中,事情往往没有那么简单
因为将书细分下来还有很多的分类类:文学类,科技类,编程类等,因此,如果只是将这些书用一个容器保存就欠妥了
那如果使用多个集合呢?似乎问题也能解决,但是在实际开发当中,往往是协同开发
举个例子,如果A的工作是建立图书的存储功能,B是建立图书的查询功能,那么这时B对A所建立的容器是不熟悉的,那么这时他该如何决定遍历容器的方式呢?
这就是问题所在,这时利用迭代器模式,A在自己的存储功能中,实现对自己容器的迭代方式,并对外暴露迭代器创建的方法(注意 迭代方式和容器是分离,容器只持有一个返回迭代器对象的方法),这样当B实现查询功能时,只需要用一套迭代器查询方法就可以了。
由此看出,迭代器模式的优点就是降低了容器与迭代算法的耦合
经过上述分析,那么就来简单实现一下这个案例吧,建立一个文学类书籍容器和编程类书籍容器,然后利用迭代器模式进行遍历
首先先来创建一个迭代器接口
public interface Iterator<T> {
boolean hasNext();
T next();
}
这个迭代器的功能很简单,就两个方法
boolean hasNext();是否有下一个元素T next()返回下一个元素
这里要提一点的就是,Java也有一个 iterator 接口
在 java.util 包下,简单看一下内部代码
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException("remove");
}
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}
可以看到官方的 iterator 内部还多了两个默认方法,分别用于删除容器元素和遍历容器元素
所以这里继承哪一个 iterator 都是可以的, 这里采用自己定义的 iterator
既然要实现两个书籍容器,为了体现迭代器模式的优势,这里将文学类书籍的存储方式设置为数组存储,将变成类书籍的存储方式设置为List存储
实现文学类书籍迭代器
public class LiteratureIterator implements Iterator {
/* 用数组存储文学类书籍 */
private Book[] literatures;
/* 数组下标 */
private int index;
public LiteratureIterator(Book[] literatures) {
this.literatures = literatures;
}
@Override
public boolean hasNext() {
/* 当前位置没有越界并且当前位置有书,则返回true */
return (index < literatures.length - 1 && literatures[index] != null);
}
@Override
public Book next() {
return literatures[index++];
}
}
实现编程类书籍迭代器
public class ProgrammingIterator implements Iterator {
/* 用数组存储文学类书籍 */
private List<Book> programmings;
/* 下标 */
private int index;
@Override
public boolean hasNext() {
return (index < programmings.size() - 1 && programmings.get(index) != null);
}
@Override
public Book next() {
return programmings.get(index++);
}
}
接下来需要考虑容器,根据分析,这里需要两个容器,在此之前需要先定义书的实体类(因为书的属性基本一致,所以这里共有一个实体类)
书籍实体类
public class Book {
private String name; /* 书名 */
private String ISBN; /* ISBN号 */
private String press; /* 出版社 */
public Book(String name, String ISBN, String press) {
this.name = name;
this.ISBN = ISBN;
this.press = press;
}
@Override
public String toString() {
return "Book{" +
"name='" + name + '\'' +
", ISBN='" + ISBN + '\'' +
", press='" + press + '\'' +
'}';
}
// getter and setter
}
下面创建容器接口,作用是使子类去实现一个返回特定的迭代对象的方法
public interface BookIterable<T> {
Iterator<T> iterator();
}
与 iterator 相对应的,Java 也有一个 Iterable 接口,并且集合接口 Collection 继承了这个接口
官方的 iterator 接口
public interface Iterable<T> {
Iterator<T> iterator();
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}
}
默认方法的功能有兴趣的可以自己去查,这里暂且不提
实现 BookIterable 接口实现文学类书籍容器
public class Literature implements BookIterable {
private Book[] literature;
public Literature() {
literature = new Book[4];
literature[0] = new Book("三国演义", "9787532237357", "上海人民美术出版社");
literature[1] = new Book("西游记", "9787805200552", "岳麓书社");
literature[2] = new Book("水浒传", "9787020015016", "人民文学出版社");
literature[3] = new Book("红楼梦", "9787020002207", "人民文学出版社");
}
public Book[] getLiterature() {
return literature;
}
@Override
public Iterator iterator() {
return new LiteratureIterator(literature);
}
}
注意 这里写了死数据,是因为根据需求,这一块是由A来处理,为了模拟A创建了两个容器的情况,这里才出此下策,实际开发当中还需要根据实际情况来考虑
实现编程类书籍容器
public class Programming implements BookIterable {
private List<Book> programmings;
public Programming() {
programmings = new ArrayList<>();
programmings.add(new Book("C++编程思想", "9787111091622", "机械工业出版社"));
programmings.add(new Book("Java编程思想", "9787111213826", "机械工业出版社"));
programmings.add(new Book("Effective Java", "9787111113850", "机械工业出版社"));
programmings.add(new Book("计算机网络自顶向下方法", "9787111165057", "机械工业出版社"));
programmings.add(new Book("Head First 设计模式(中文版)", "9787508353937", "中国电力出版社"));
}
public List<Book> getProgrammings() {
return programmings;
}
@Override
public Iterator iterator() {
return new ProgrammingIterator(programmings);
}
}
这里仍然是写了死数据,原因上面也介绍了,这两个容器的创建都是A的任务,那么接下来就是B出场了,B的工作就是对容器进行检索,那么当他拿到A创建的两组容器后,就可以利用相同的迭代方式迭代容器,下面来看看B的操作
public class QueryTest {
public static void main(String[] args) {
/* 创建文学类书籍容器 */
Literature literature = new Literature();
/* 迭代文学类书籍容器 */
itr(literature.iterator());
System.out.println("\n+----------Divider----------+\n");
/* 创建编程类书籍容器 */
Programming programming = new Programming();
/* 迭代编程类书籍容器 */
itr(programming.iterator());
}
/* 书籍容器共有的迭代方法 */
private static void itr(Iterator iterator) {
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
测试结果
Book{name='三国演义', ISBN='9787532237357', press='上海人民美术出版社'}
Book{name='西游记', ISBN='9787805200552', press='岳麓书社'}
Book{name='水浒传', ISBN='9787020015016', press='人民文学出版社'}
+----------Divider----------+
Book{name='C++编程思想', ISBN='9787111091622', press='机械工业出版社'}
Book{name='Java编程思想', ISBN='9787111213826', press='机械工业出版社'}
Book{name='Effective Java', ISBN='9787111113850', press='机械工业出版社'}
Book{name='计算机网络自顶向下方法', ISBN='9787111165057', press='机械工业出版社'}
到此,即实现了一个简单的迭代器模式,其实更加细致的实现细节,可以参考集合类的实现方式,这里不再赘述
总结
关于迭代器模式,总结一下优缺点
- 优点:优点在上一小节中提高过,就是迭代器模式降低了容器类和迭代算法的耦合度
- 缺点:每一个容器都有可能有一个对应的迭代器实现,这也导致了类的增加
END.